bottleneck feature
通过多层感知机训练得到的bottleneck feature 通常是被作为非线性特征转换或降维的手段, 这种非线性比传统的PCA更有效。
这种bottleneck feature来自于autoencoder结构的中间层, 即下图中的Code layer
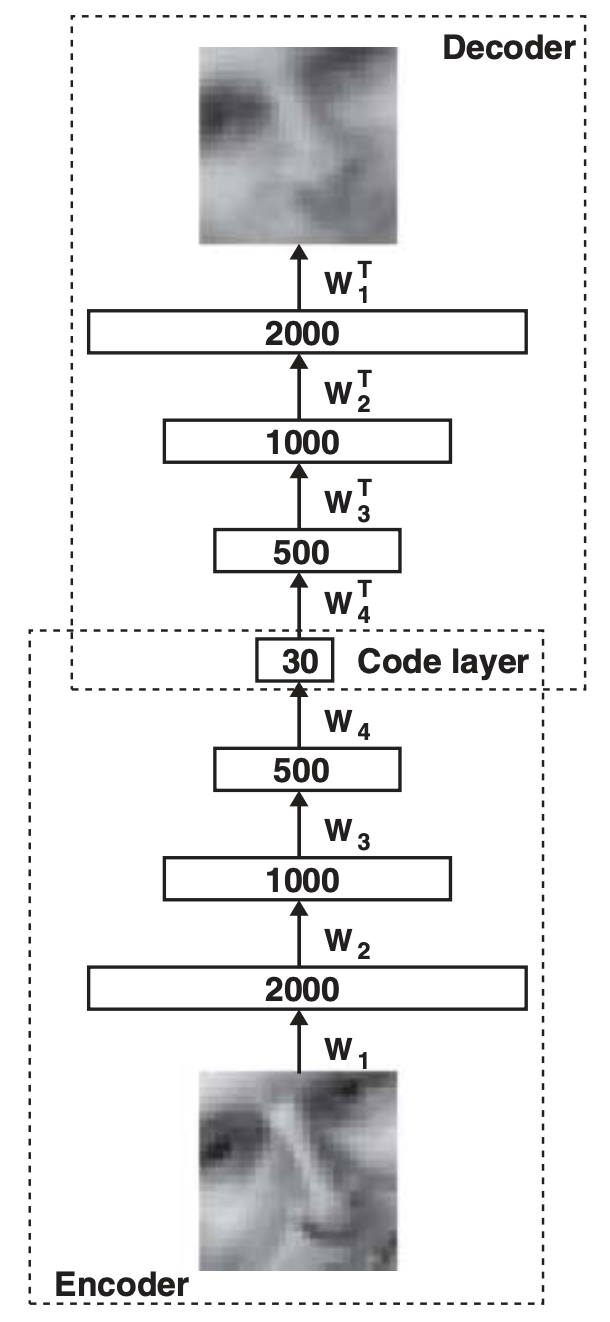
当autoencoder中的隐层层数过多时(2-4),通常不容易训练。解决的方法是逐层的pretrain 1
bottleneck feature for ASR
在这篇文章中,作者探讨了bottleneck feature对ASR的帮助
实验
实验数据
音频特点:8k, GSM格式, 各种variability:噪声, 音乐,旁语, 口音, 停顿, 重复等, 平均每句2.1个词。
train集: 24小时, 32,057句
dev集:6.5小时, 8777句
eval集:9.5小时,12,758句
Baseline
53K个逻辑triphone, 2k物理triphone, 被聚类到761个绑定的GMM状态,每个GMM有24个component。
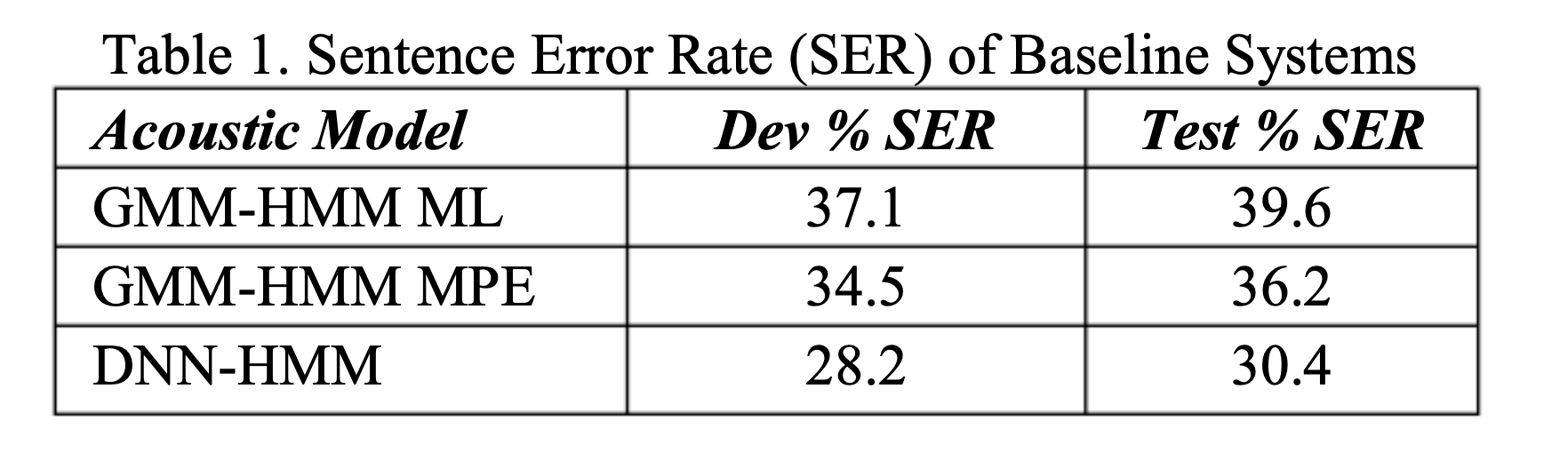
baseline 有三套系统分别是使用最大似然(maximum likihood)和最小音素错误(minimum phone error)准则训练的GMM-HMM系统,
以及为了对比,同时进行了5 层pretrained DNN-HMM系统(起输出为预测761个GMM状态的概率分布),结果为:
bottleneck 层数的实验
使用bottleneck feature作为辅助特征的结构如下:
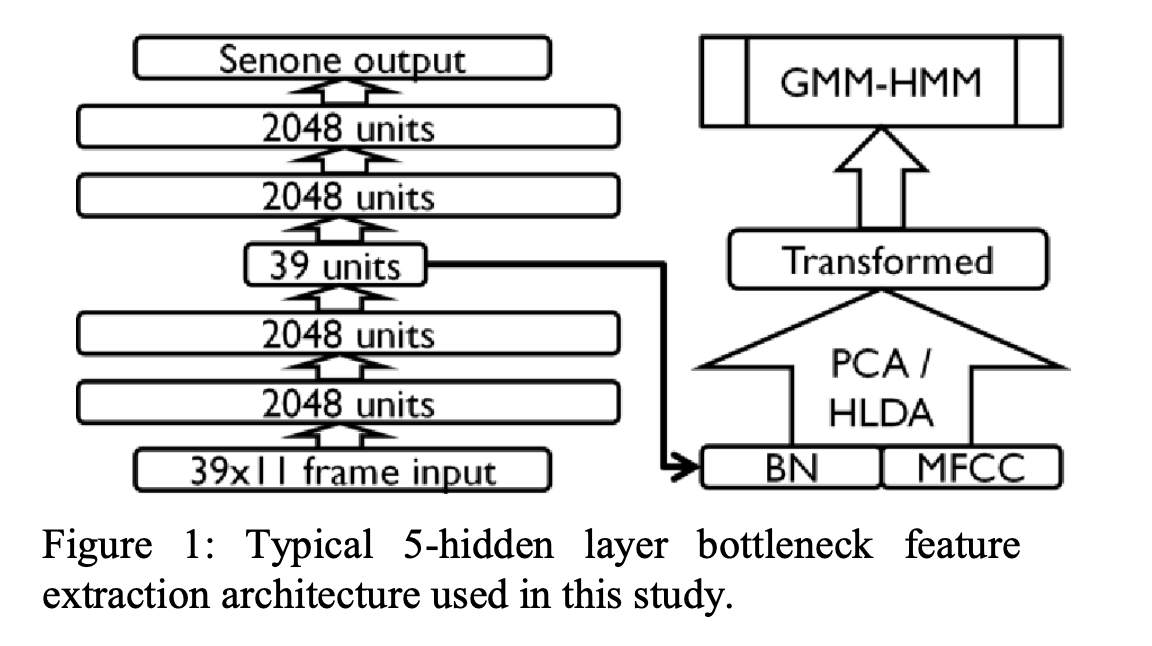
图中的autoencoder为5层的结构, GMM-HMM使用ML方法优化, 所提出的BN feature+MFCC的特征 会使用PCA进行去相关化后在作为辅助特征进行使用。
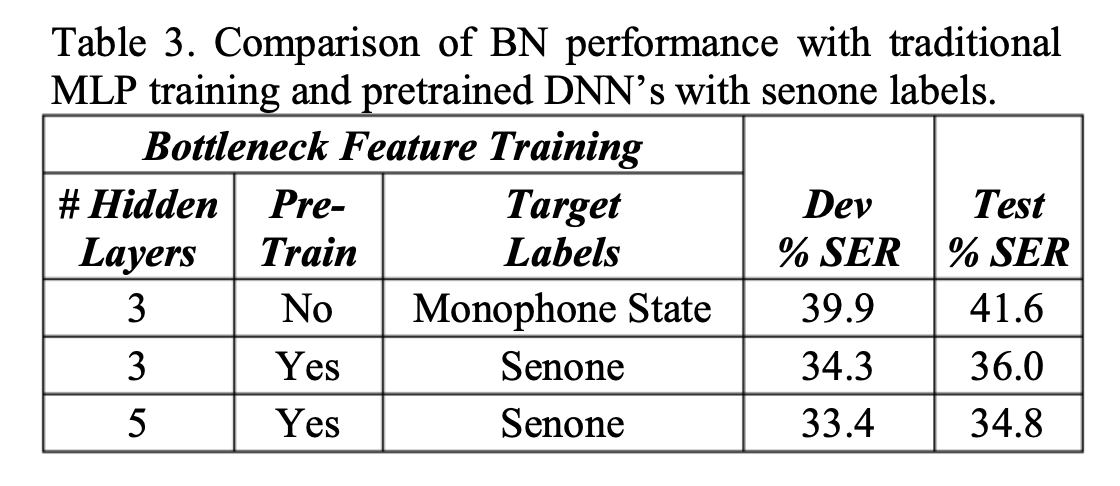
为了验证层数和pretrain对所BN特征的影响,文中进行了关于层数和pretrain在dev集上的实验,如下:
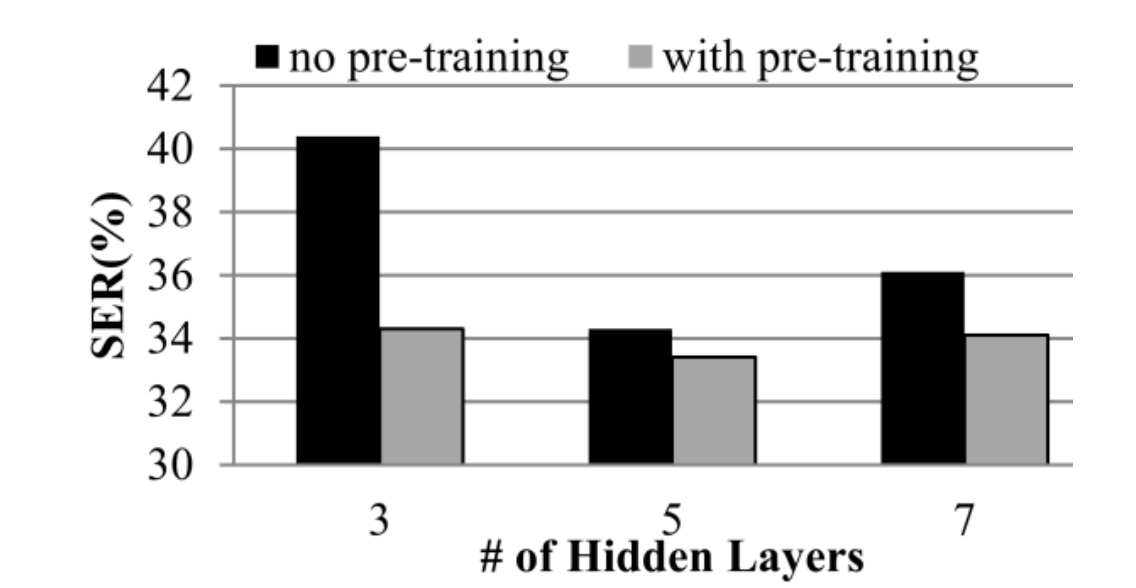
实验结果可以发现,使用5层的含pretrain的BN特征性能最好,之后的实验均使用5层的autoencoder
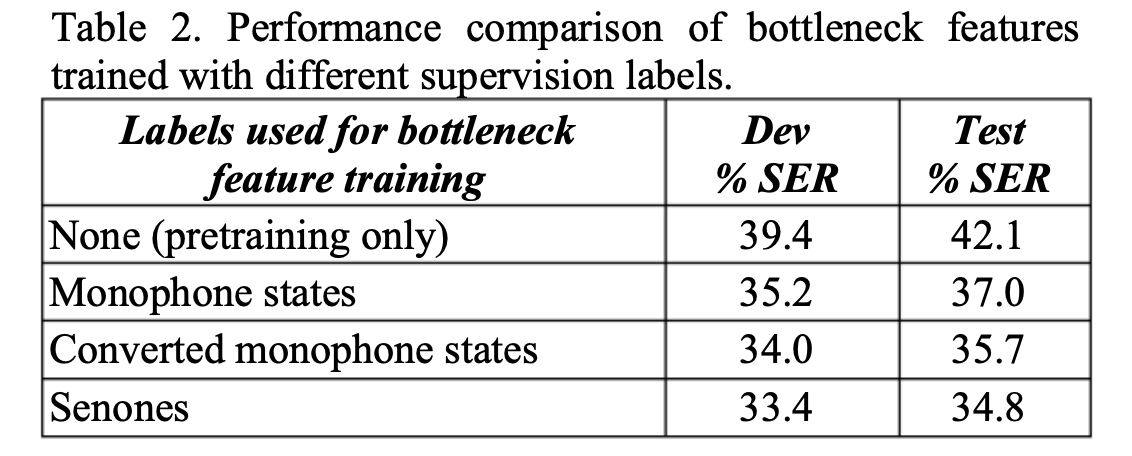
关于autoencoder的标签对于BN特征的影响的实验
实验中,如果不使用有监督的fine-tune,只使用generative critera(即autoencoder的生成性特征),也可以在dev集上取得39.4%的SER,如图第一行所示;
如果使用monophone GMM-HMM系统的monophone state做alignment的结果如第二行所示;
使用triphone GMM-HMM的alignment转为monophone state的alingment训练autoencoder的结果如第三行所示;
使用triphone state 的GMM-HMM(即senone)作为alignment的结果如第四行所示
具体观察层数,pretrain和label对BN的影响:
观察有没有BN对ASR的影响,以及训练准则对ASR的影响:
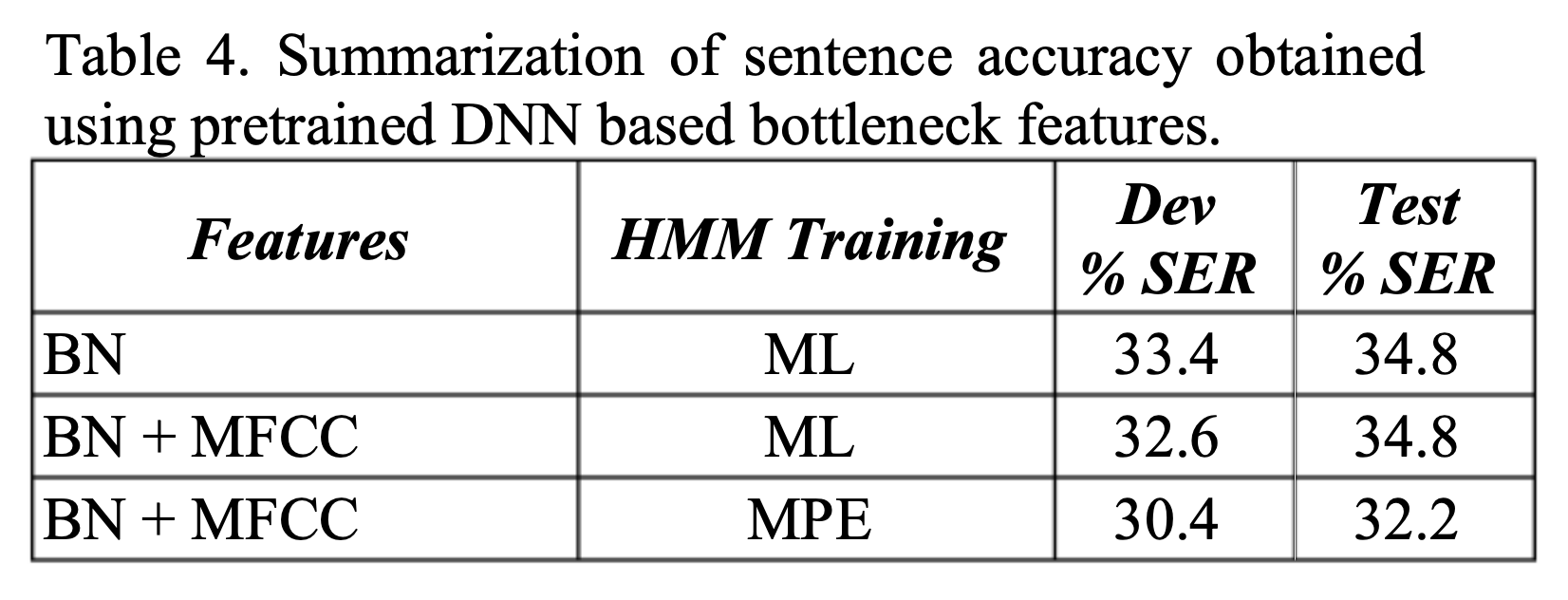
可以发现在使用ML准则时,有BN的情况下,在test测试集中有没有MFCC性能是一样的。
同时使用MPE准则训练,最终的ASR性能会更好。
结论
使用unsupervised pretrain有2点好处:1.性能提升; 2. 当层数多时,比随机初始化性能要好
使用senone alignment fine-tuned的和pretrain的autocoder所提出的BN 对与triphone的GMM-HHM性能最好